
Chaos Engineering on AWS: Multi-Region Disaster Recovery and Measuring Real RPO
Tarek Cheikh
Founder & AWS Cloud Architect
This is Article 9 in the "Chaos Engineering on AWS" series. Every experiment so far has stayed inside a single Region. Here we go all the way up: two Regions, a global database, and a fault that severs the link between them so we can put a real number on the question every DR plan answers on paper but rarely tests.
The Two Numbers That Define Disaster Recovery
Disaster recovery is sold in two numbers. RTO, the recovery time objective, is how long you are down. RPO, the recovery point objective, is how much data you lose. A runbook that says "RPO is near zero because we use DynamoDB global tables" is a hypothesis, not a fact, and the only honest way to know the real figure is to break replication on purpose and count what is missing.
That used to be hard. You cannot unplug a Region, and pulling apart a global table by hand is risky and slow. In 2024 AWS FIS added an action built exactly for this: aws:dynamodb:global-table-pause-replication. It pauses replication between the replicas of a global table for a fixed duration, then restores it cleanly. That is the precise, reversible, measurable fault this article uses.
The Architecture: One App, Two Regions, One Global Table
The stack is deliberately small and fully serverless, so it is cheap to run and there are no servers to confuse the picture. It exists identically in two Regions, us-east-1 (primary) and us-west-2 (secondary):
- A DynamoDB global table (
chaos-lab-orders) with a replica in each Region. Writes in one Region replicate asynchronously to the other. This is the data tier that is supposed to survive a Region loss. - A Lambda function in each Region that reads and writes its local replica. It exposes
GET /put(write one order record) andGET /count(count what this Region's replica can see). - An API Gateway HTTP API in front of each Lambda, giving us a live endpoint per Region.
There is no Route 53, no custom domain, and no health-check failover in this lab. That is on purpose. Cutover routing is a solved, well-documented problem; the thing teams get wrong is the data, so we drive the two Region endpoints directly and focus the experiment entirely on what replication does and does not guarantee. Full source is at github.com/TocConsulting/chaos-on-aws, in 09-multi-region-dr/terraform/.
The global table is the modern single-resource form (the 2019.11.21 version), one aws_dynamodb_table with a replica block per extra Region, not the deprecated standalone aws_dynamodb_global_table:
resource "aws_dynamodb_table" "global" {
name = "chaos-lab-orders"
billing_mode = "PAY_PER_REQUEST"
hash_key = "id"
stream_enabled = true
stream_view_type = "NEW_AND_OLD_IMAGES"
attribute {
name = "id"
type = "S"
}
replica {
region_name = var.region_secondary
}
}The Fault: Pausing Replication
One detail is worth getting right before you waste an afternoon on it. The FIS action targets the resource type aws:dynamodb:global-table, but the literal target key inside the action block is Tables, not GlobalTables and not DynamoDBGlobalTables. That one string is load bearing. Unlike the Lambda actions in Article 8, the Terraform provider does accept this template, so the whole experiment is defined in Terraform:
resource "aws_fis_experiment_template" "pause_replication" {
description = "Pause DynamoDB global table replication"
role_arn = aws_iam_role.fis.arn
stop_condition { source = "none" }
target {
name = "globalTableTarget"
resource_type = "aws:dynamodb:global-table"
selection_mode = "ALL"
resource_arns = [aws_dynamodb_table.global.arn]
}
action {
name = "pauseReplication"
action_id = "aws:dynamodb:global-table-pause-replication"
parameter {
key = "duration"
value = "PT20M"
}
target {
key = "Tables"
value = "globalTableTarget"
}
}
}The target is the ordinary base table ARN (aws_dynamodb_table.global.arn), not a stream ARN and not a special global-table ARN. The only parameter is duration. The FIS role needs dynamodb:PutResourcePolicy, DeleteResourcePolicy, GetResourcePolicy, and DescribeTable, plus tag:GetResources if you select by tag, because of how the fault actually works, which is the interesting part.
How It Actually Works
The action does not call a "pause" API. It attaches a resource policy to the table that denies the DynamoDB replication service the right to act, for the duration of the experiment. While the experiment ran, the table carried this statement, captured live from the account:
{
"Sid": "DoNotModifyFisDynamoDbPauseReplicationEXP9uCqGqDDsRTG45x",
"Effect": "Deny",
"Principal": { "AWS": "*" },
"Action": ["dynamodb:GetItem","dynamodb:PutItem","dynamodb:UpdateItem",
"dynamodb:DeleteItem","dynamodb:Scan", ...],
"Resource": "arn:aws:dynamodb:us-east-1:...:table/chaos-lab-orders",
"Condition": {
"ArnEquals": { "aws:PrincipalArn":
"arn:aws:iam::...:role/aws-service-role/replication.dynamodb.amazonaws.com/AWSServiceRoleForDynamoDBReplication" },
"DateLessThan": { "aws:CurrentTime": "2026-06-19T21:39:10Z" }
}
}Read the condition carefully. The Deny applies only to the principal AWSServiceRoleForDynamoDBReplication, the service-linked role DynamoDB uses to copy data between replicas. Your application's own reads and writes are untouched. And the DateLessThan condition means the policy expires on its own at the experiment end time, so even if FIS could not clean up, the fault is self-healing. When the experiment ends, FIS removes the statement and replication resumes. This is a precise, reversible cut, and seeing the mechanism makes the results obvious.
Running the Experiment
The procedure is simple. Establish a baseline, start the experiment, keep writing to the primary, and watch the secondary. First the baseline, with replication healthy:
5 records written to PRIMARY (us-east-1)
PRIMARY count: 5
SECONDARY count: 5 (after ~5 seconds)Normal global table behavior: a write in one Region shows up in the other within a few seconds. Now start the fault and keep writing one new record to the primary every 20 seconds while polling both Regions:
elapsed | primary_count | secondary_count | gap
3s | 6 | 5 | 1
89s | 10 | 5 | 5
195s | 15 | 5 | 10
303s | 20 | 5 | 15
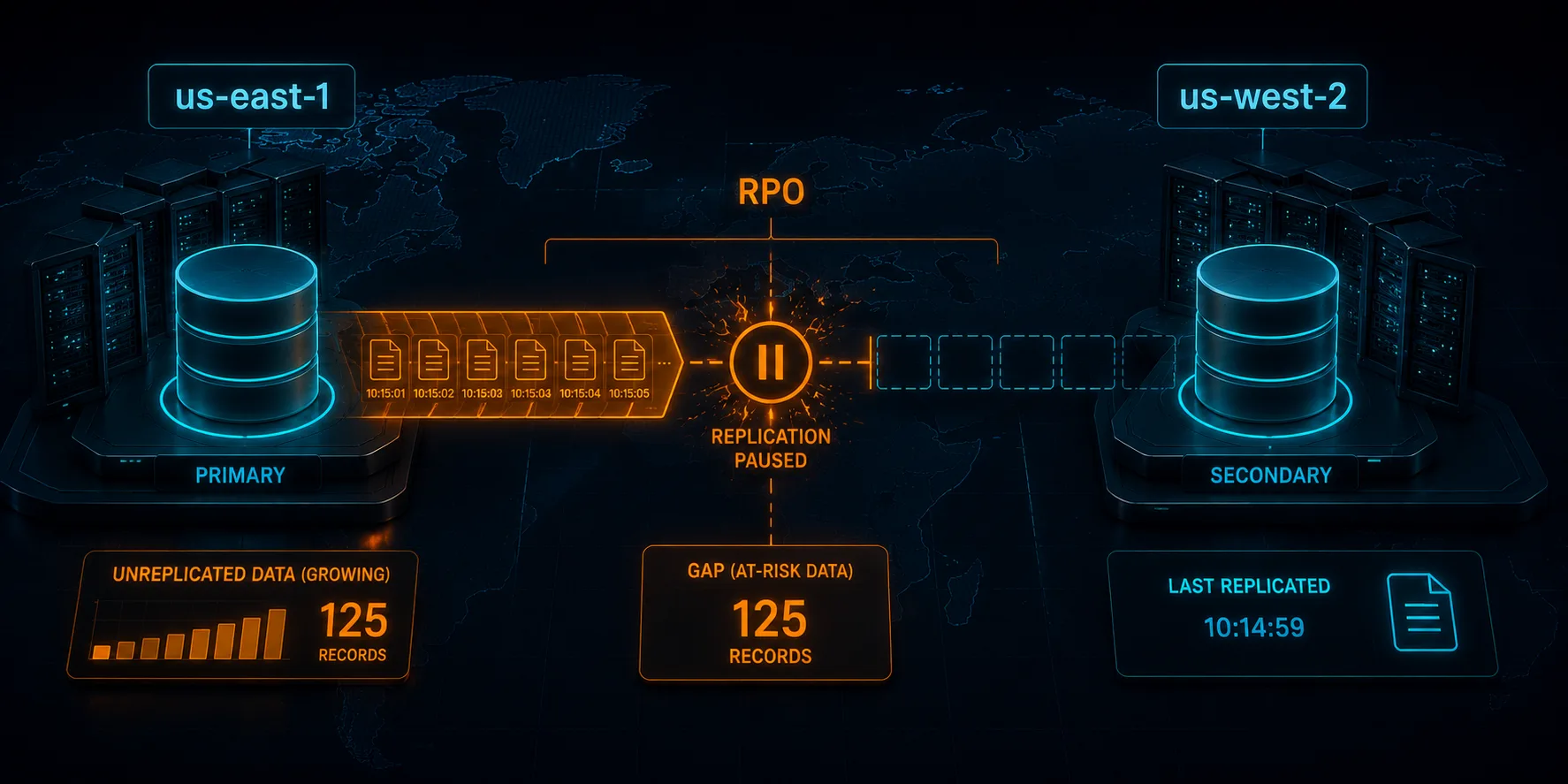
367s | 23 | 5 | 18The secondary froze at exactly 5, the baseline, and never moved. The primary kept happily accepting writes, climbing to 23. Every record written after the pause engaged piled up in the primary with no path to the secondary. The documentation warns that replication can continue for up to five minutes after the action begins; in this run the cut was effectively immediate, the very first write during the experiment never crossed.
The Result: RPO Is Not Zero
At the moment the experiment was stopped, the gap was 18 records. Those are 18 successful, acknowledged writes that the primary holds and the secondary has never seen. If the primary Region had failed at that instant and we had cut traffic over to the secondary, those 18 orders would simply be gone. Not delayed. Gone, until the primary comes back, which in a real regional event might be hours or never.
That is the number the runbook never had. "RPO is near zero" is true only while replication is healthy. The instant replication is impaired, RPO grows at the rate you write, and a failover during that window loses everything in the gap. The lab made it a count you can see; in production it is the size of your write rate multiplied by how long the impairment lasts before someone decides to fail over.
Recovery
Stopping the experiment removes the deny statement, and DynamoDB catches up on its own. The secondary stayed at 5 for a while after the stop (the policy removal also takes effect with a short delay), then jumped straight to 23:
stop experiment
+ 1s secondary=5 / primary=23
+ 96s secondary=5 / primary=23
+112s secondary=23 / primary=23 CAUGHT UPThe backlog drained and the two Regions reconverged in about 112 seconds. That is the good news: once replication is restored, global tables heal themselves and no data written to the surviving primary is lost. The trap is only the window in between, and only if you fail over during it.
What This Tells You About Your DR Plan
The experiment is small, but the lesson scales directly to any active-passive or active-active design built on asynchronous cross-Region replication, which is almost all of them:
- Asynchronous replication makes RPO a function of replication lag, not a constant. Healthy lag is seconds. Impaired lag is unbounded. Your true RPO is whatever the lag is at the moment you fail over, so the question that matters is "how do we know the lag, and do we hold off failover until it drains?"
- Failing over too eagerly can cost more than the outage. If the primary is merely slow rather than gone, cutting to the secondary mid-impairment trades a degraded service for permanent data loss. A good runbook checks replication health before it pulls the trigger.
- The recovery side is the reassuring part. Global tables reconverged with zero intervention and zero loss to the primary once replication resumed. The resilience is real; the failure mode is specifically the failover decision during the gap.
None of this is visible from an architecture diagram. It only shows up when you pause replication on a live system and count. That is the whole point of chaos engineering applied to disaster recovery: turn the two numbers on the runbook from assertions into measurements.
What Is Next
We have now broken compute, storage, dependencies, availability zones, and entire Regions. The final article steps back from any single experiment to the practice itself: how to run Article 10, a chaos engineering program, with GameDays, continuous automated experiments in a pipeline, and the cultural and safety guardrails that let you do this on production without fear.
Cleanup
cd chaos-on-aws/09-multi-region-dr/terraform
terraform destroyA global table with a replica takes a minute or two to delete because both Regions' replicas must be removed. Everything in this lab (DynamoDB, two Lambdas, two HTTP APIs, the IAM roles, the FIS template) is in Terraform state, so a single destroy removes all of it. Tear it down so it does not run up a bill.
References
Go Deeper: The State of AWS Security 2026
This article is just the start. Get the full picture with our free whitepaper - 8 chapters covering IAM, S3, VPC, monitoring, agentic AI security, compliance, and a prioritized action plan with 50+ CLI commands.
Toc Consulting: AWS Security & Cloud Architecture
Want expert help with Chaos Engineering?
Our team helps engineering teams secure and architect AWS the right way: assessment in week one, a prioritized action plan in week two.
More Articles
Chaos Engineering on AWS: Running a Program with GameDays and Continuous Chaos
One experiment is a demo. A program is what builds resilience. Turn FIS experiments into an ongoing practice: the resilience flywheel, GameDays, continuous automated chaos on a schedule and in CI/CD, and AWS Resilience Hub. Includes a real, validated EventBridge Scheduler setup and the jsonencode gotcha that makes a recurring schedule silently run only once.
Chaos Engineering on AWS: Containers and Serverless with FIS (ECS Fargate and Lambda)
Leave EC2 behind. Stop a whole Fargate task set and force AWS Lambda invocations to error and to stall, using AWS FIS. Real Terraform, real numbers, and the exact setup gotchas for the Lambda fault-injection extension.
Chaos Engineering on AWS: Dependency and API Faults with FIS
Sever the DynamoDB and S3 endpoints an application quietly depends on, using AWS FIS, and watch whether one dependency outage stays contained or takes the whole app down. Real Terraform, real per-endpoint numbers.